Converts a cluster_summary object to proper tna objects that can be
used with all functions from the tna package. Creates a macro (cluster-level)
tna model and per-cluster tna models (internal transitions within each
cluster), returned as a flat group_tna object.
Usage
as_tna(x)
# S3 method for class 'cluster_summary'
as_tna(x)
# S3 method for class 'mcml'
as_tna(x)
# Default S3 method
as_tna(x)Arguments
- x
A
cluster_summaryobject created bycluster_summary. The cluster_summary should typically be created withtype = "tna"to ensure row-normalized transition probabilities. If created withtype = "raw", the raw counts will be passed totna::tna()which will normalize them.
Value
A group_tna object (S3 class) – a flat named list of tna
objects. The first element is named "macro" and represents the
cluster-level transitions. Subsequent elements are named by cluster name
and represent internal transitions within each cluster.
- macro
A tna object representing cluster-level transitions. Contains
$weights(k x k transition matrix),$inits(initial distribution), and$labels(cluster names). Use this for analyzing how learners/entities move between high-level groups or phases.- <cluster_name>
Per-cluster tna objects, one per cluster. Each tna object represents internal transitions within that cluster. Contains
$weights(n_i x n_i matrix),$inits(initial distribution), and$labels(node labels). Clusters with single nodes or zero-row nodes are excluded (tna requires positive row sums).
A group_tna object (flat list of tna objects: macro + per-cluster).
A group_tna object (flat list of tna objects: macro + per-cluster).
A tna object constructed from the input.
Details
This is the final step in the MCML workflow, enabling full integration with the tna package for centrality analysis, bootstrap validation, permutation tests, and visualization.
Requirements
The tna package must be installed. If not available, the function throws an error with installation instructions.
Workflow
# Full MCML workflow
net <- cograph(edges, nodes = nodes)
net$nodes$clusters <- group_assignments
cs <- cluster_summary(net, type = "tna")
tna_models <- as_tna(cs)
# Now use tna package functions
plot(tna_models$macro)
tna::centralities(tna_models$macro)
tna::bootstrap(tna_models$macro, iter = 1000)
# Analyze per-cluster patterns
plot(tna_models$ClusterA)
tna::centralities(tna_models$ClusterA)See also
cluster_summary to create the input object,
plot_mcml for visualization without conversion,
tna::tna for the underlying tna constructor
Examples
# -----------------------------------------------------
# Basic usage
# -----------------------------------------------------
mat <- matrix(runif(36), 6, 6)
diag(mat) <- 0
rownames(mat) <- colnames(mat) <- LETTERS[1:6]
clusters <- list(
G1 = c("A", "B"),
G2 = c("C", "D"),
G3 = c("E", "F")
)
cs <- cluster_summary(mat, clusters, type = "tna")
tna_models <- as_tna(cs)
# Print summary
tna_models
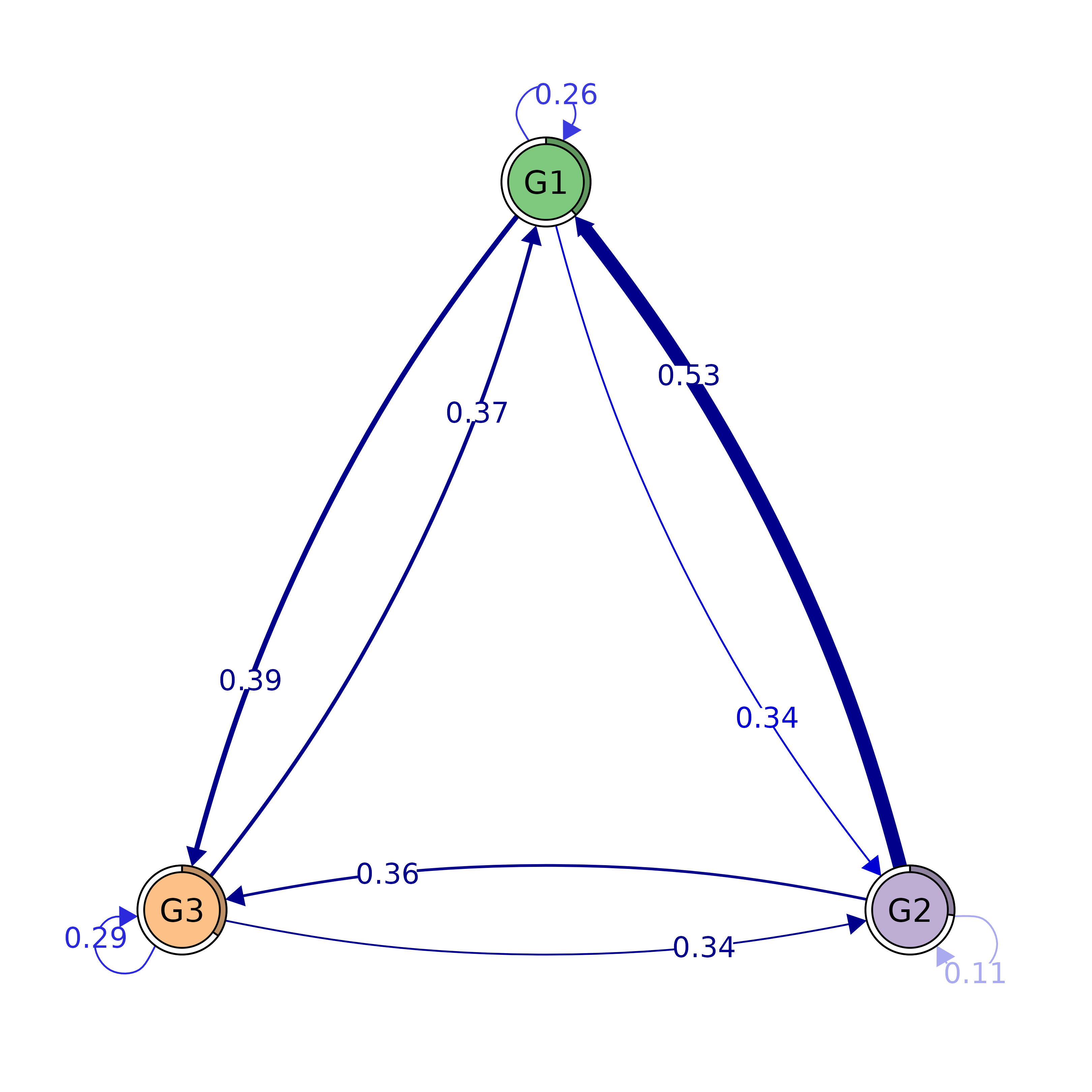
#> macro :
#> State Labels :
#>
#> G1, G2, G3
#>
#> Transition Probability Matrix :
#>
#> G1 G2 G3
#> G1 0.2648415 0.3417357 0.3934228
#> G2 0.5303259 0.1137710 0.3559031
#> G3 0.3725089 0.3419766 0.2855146
#>
#> Initial Probabilities :
#>
#> G1 G2 G3
#> 0.3823688 0.2691329 0.3484984
#>
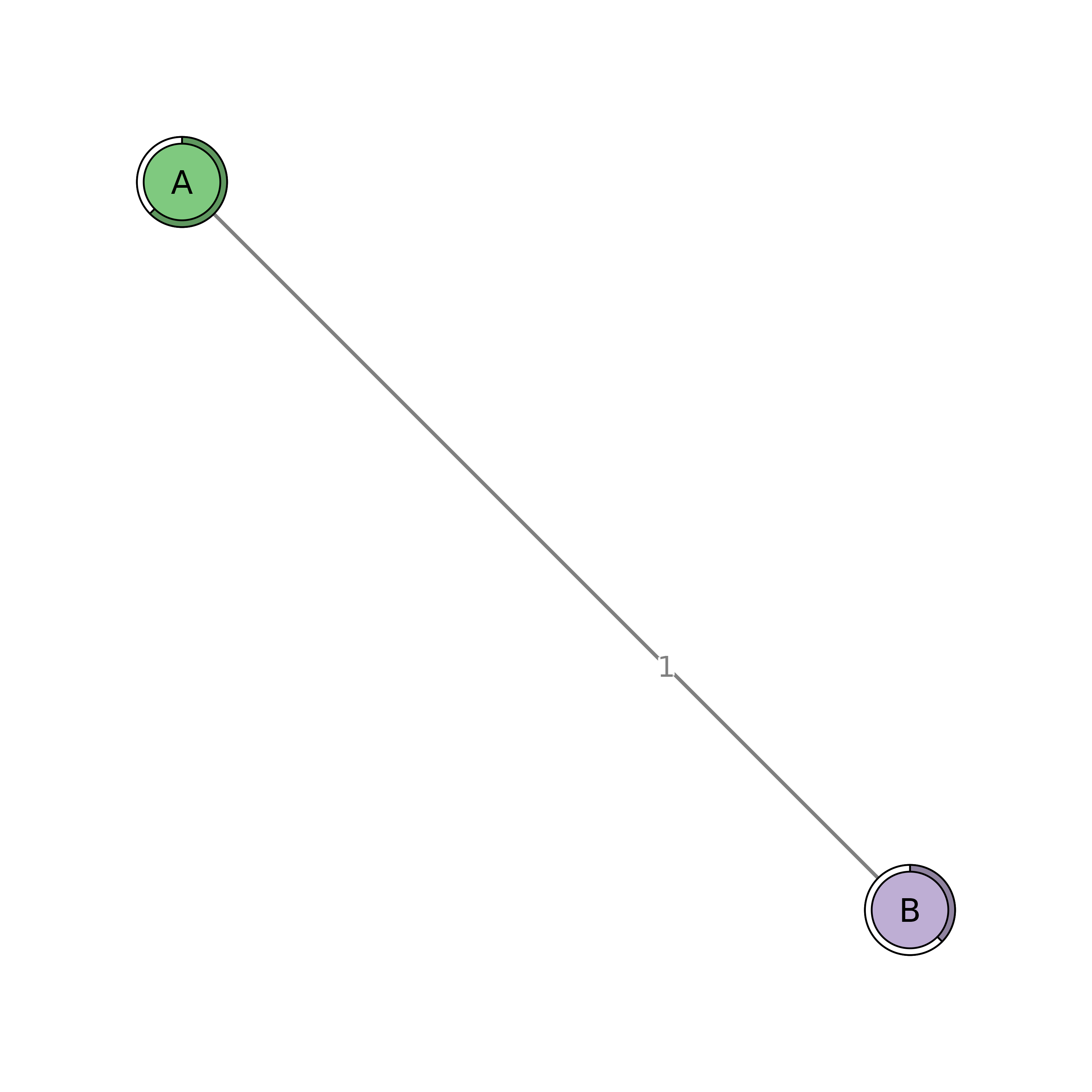
#> G1 :
#> State Labels :
#>
#> A, B
#>
#> Transition Probability Matrix :
#>
#> A B
#> A 0 1
#> B 1 0
#>
#> Initial Probabilities :
#>
#> A B
#> 0.6263242 0.3736758
#>
#> G2 :
#> State Labels :
#>
#> C, D
#>
#> Transition Probability Matrix :
#>
#> C D
#> C 0 1
#> D 1 0
#>
#> Initial Probabilities :
#>
#> C D
#> 0.4029759 0.5970241
#>
#> G3 :
#> State Labels :
#>
#> E, F
#>
#> Transition Probability Matrix :
#>
#> E F
#> E 0 1
#> F 1 0
#>
#> Initial Probabilities :
#>
#> E F
#> 0.5897289 0.4102711
#>
# -----------------------------------------------------
# Access components
# -----------------------------------------------------
# Macro (cluster-level) tna
tna_models$macro
#> State Labels :
#>
#> G1, G2, G3
#>
#> Transition Probability Matrix :
#>
#> G1 G2 G3
#> G1 0.2648415 0.3417357 0.3934228
#> G2 0.5303259 0.1137710 0.3559031
#> G3 0.3725089 0.3419766 0.2855146
#>
#> Initial Probabilities :
#>
#> G1 G2 G3
#> 0.3823688 0.2691329 0.3484984
tna_models$macro$weights # 3x3 transition matrix
#> G1 G2 G3
#> G1 0.2648415 0.3417357 0.3934228
#> G2 0.5303259 0.1137710 0.3559031
#> G3 0.3725089 0.3419766 0.2855146
tna_models$macro$inits # Initial distribution
#> G1 G2 G3
#> 0.3823688 0.2691329 0.3484984
tna_models$macro$labels # c("G1", "G2", "G3")
#> [1] "G1" "G2" "G3"
# Per-cluster tnas
names(tna_models) # "macro", "G1", "G2", "G3"
#> [1] "macro" "G1" "G2" "G3"
tna_models$G1 # tna for cluster G1
#> State Labels :
#>
#> A, B
#>
#> Transition Probability Matrix :
#>
#> A B
#> A 0 1
#> B 1 0
#>
#> Initial Probabilities :
#>
#> A B
#> 0.6263242 0.3736758
tna_models$G1$weights # 2x2 matrix (A, B)
#> A B
#> A 0 1
#> B 1 0
# -----------------------------------------------------
# Use with tna package (requires tna)
# -----------------------------------------------------
if (requireNamespace("tna", quietly = TRUE)) {
# Plot
plot(tna_models$macro)
plot(tna_models$G1)
# Centrality analysis
tna::centralities(tna_models$macro)
tna::centralities(tna_models$G1)
tna::centralities(tna_models$G2)
}
 #> # A tibble: 2 × 10
#> state OutStrength InStrength ClosenessIn ClosenessOut Closeness Betweenness
#> * <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 C 1 1 1 1 1 0
#> 2 D 1 1 1 1 1 0
#> # ℹ 3 more variables: BetweennessRSP <dbl>, Diffusion <dbl>, Clustering <dbl>
if (FALSE) { # \dontrun{
# Bootstrap requires a tna object built from raw sequence data (has $data)
# as_tna() returns weight-matrix-based tnas which don't satisfy that requirement
if (requireNamespace("tna", quietly = TRUE)) {
boot <- tna::bootstrap(tna_models$macro, iter = 1000)
summary(boot)
}
} # }
# -----------------------------------------------------
# Check which within-cluster models were created
# -----------------------------------------------------
cs <- cluster_summary(mat, clusters, type = "tna")
tna_models <- as_tna(cs)
# All cluster names
names(cs$cluster_members)
#> [1] "G1" "G2" "G3"
# Clusters with valid per-cluster models
setdiff(names(tna_models), "macro")
#> [1] "G1" "G2" "G3"
# Clusters excluded (single node or zero rows)
setdiff(names(cs$cluster_members), names(tna_models))
#> character(0)
#> # A tibble: 2 × 10
#> state OutStrength InStrength ClosenessIn ClosenessOut Closeness Betweenness
#> * <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 C 1 1 1 1 1 0
#> 2 D 1 1 1 1 1 0
#> # ℹ 3 more variables: BetweennessRSP <dbl>, Diffusion <dbl>, Clustering <dbl>
if (FALSE) { # \dontrun{
# Bootstrap requires a tna object built from raw sequence data (has $data)
# as_tna() returns weight-matrix-based tnas which don't satisfy that requirement
if (requireNamespace("tna", quietly = TRUE)) {
boot <- tna::bootstrap(tna_models$macro, iter = 1000)
summary(boot)
}
} # }
# -----------------------------------------------------
# Check which within-cluster models were created
# -----------------------------------------------------
cs <- cluster_summary(mat, clusters, type = "tna")
tna_models <- as_tna(cs)
# All cluster names
names(cs$cluster_members)
#> [1] "G1" "G2" "G3"
# Clusters with valid per-cluster models
setdiff(names(tna_models), "macro")
#> [1] "G1" "G2" "G3"
# Clusters excluded (single node or zero rows)
setdiff(names(cs$cluster_members), names(tna_models))
#> character(0)